AITrain AI训练
AITrain 算子用于对几类 CNN 神经网络模型的训练。算子执行过程中包含数据格式转换以及训练两个环节。
| type | 功能 |
|---|---|
| MaskRCNNTrain | 用于 MaskRCNN 网络的训练,可以获得图像中目标的位置掩码(像素区域) |
| YOLOTrain | 用于 YOLO 网络的训练,可以获得图像中目标位置的旋转矩形框 |
| KeyPointTrain | 用于关键点网络的训练,在 MaskRCNN 网络的基础上可以额外获得关键点的像素值 |
<div
说明
MaskRCNN 网络训练耗时短,所需训练数据量少,推理准确度高,但是推理速度慢。KeyPoint 网络训练耗时较短,所需训练数据量较少,推理准确度高,推理速度慢。RotatedYOLO 网络训练时间长,所需训练数据量较大,推理准确度明显低于前两个网络,但是推理速度很快,并且可以获取旋转矩形框,对于大多数长方体目标的检测是适用的。
当计算机上有两块或更多的独立显卡时,可在与类名文件相同的目录下创建一个名为CUDA_DEVICE.txt的文件。在这个文件中,输入cuda:n-1来选择使用哪一块独立显卡进行训练。训练实际使用的独显序号会自动保存到训练生成的配置文件 config.yaml 中。若输入的是0,表示选择第一块独立显卡进行训练。
如下图所示:
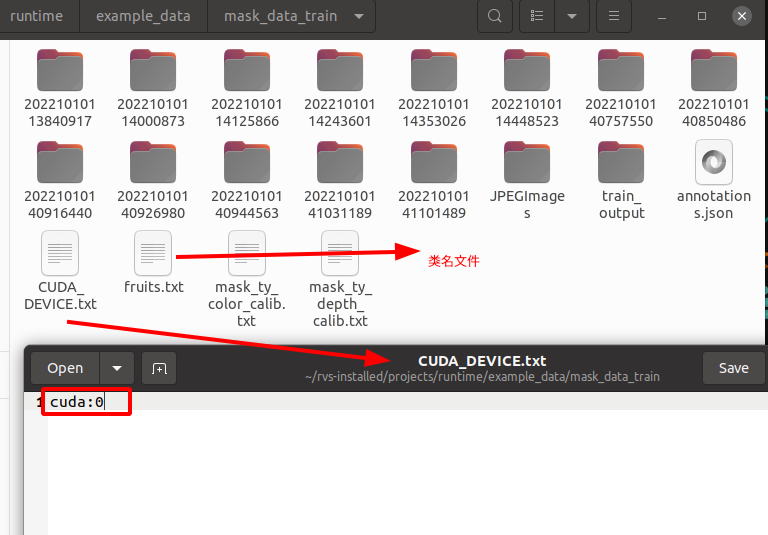
注意:推理时应与训练独立显卡一致,若想选择不同的独立显卡进推理,需要修改配置文件 config.yaml 。
训练实际使用的独显序号会自动保存到训练生成的配置文件 config.yaml 中。
推理时,推理电脑会根据 config.yaml 中记录的独显序号来调用推理电脑上独显。一般情况下,由于训练电脑使用的都是第
0块独显,并且大多数推理电脑也只有一块独显,所以即便更换电脑推理时也不需要去修改 config.yaml。如果客户在训练时通过编写 CUDA_DEVICE.txt 文件来指定使用第 n 块显卡,且推理时使用的电脑没有 n 块显卡或者想更换使用第 m 块显卡,则必须打开训练后生成的config.yaml进行修改。
操作步骤:
在 train_output 文件夹中找到 config.yaml,根据 cuda 关键字查找到
DEVICE:cuda:0,将0改成指定的第 m 块显卡。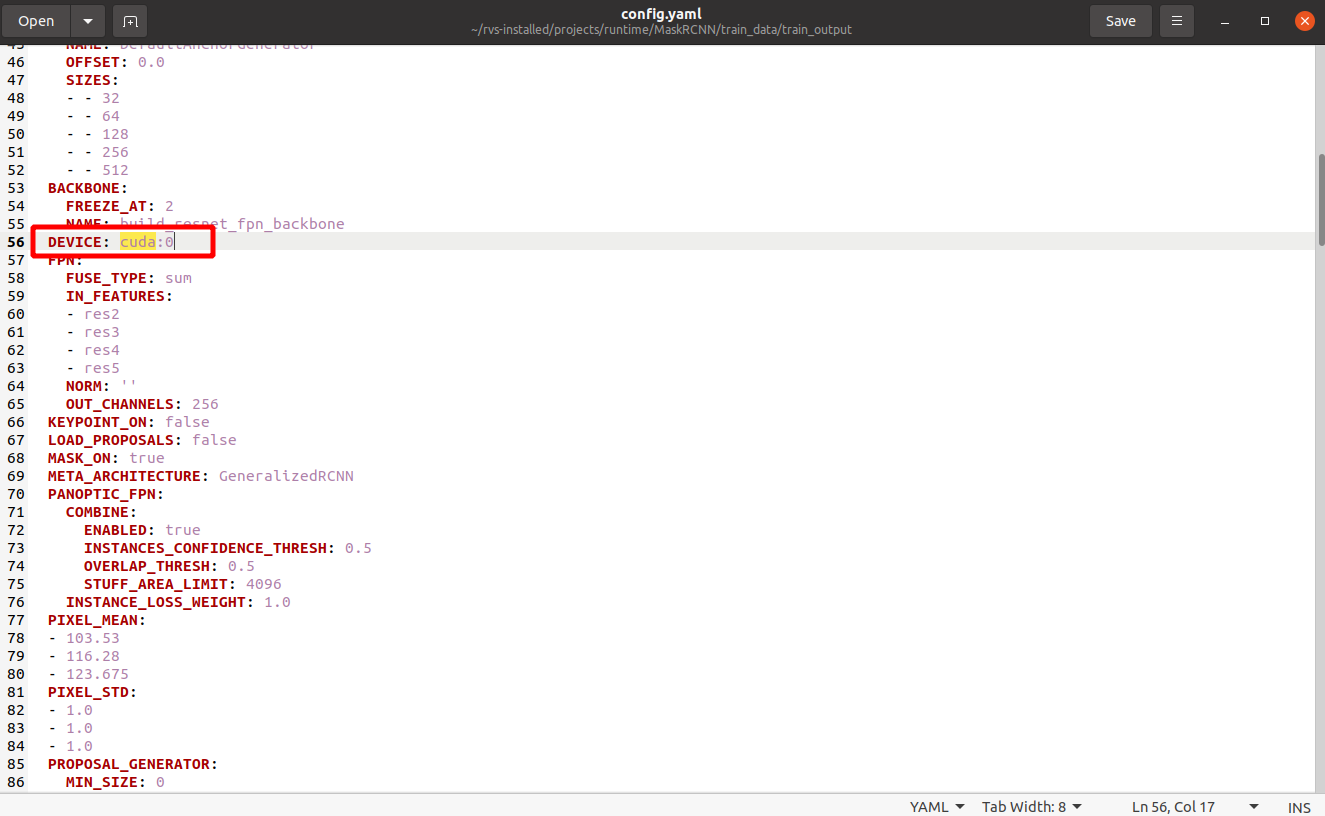
MaskRCNNTrain
算子参数
数据目录/data_directory:训练数据文件夹路径。注意:该路径内包含多个子文件夹,每个子文件夹代表一组图像数据,其中必须包含有一张命名为 xxx.png 的图像以及一个命名为 xxx.json 的标注文件。
路径中不支持中文与空格。
类名文件路径/classnames_filepath:训练数据的类名文件地址。注意:训练所用的类名文件必须以 txt 作为文件后缀,文件中每一个类别名各自占一行。类名中不允许包含空格,且必须同标注文件中的类名保持一致。
路径中不支持中文与空格。
长边长度/long side size:训练图像的长边像素长度。注意:在执行训练时,以及训练完成后进行推理时,算子都会首先将原图按照这里设定的尺寸进行缩放。所以这里的尺寸设置直接影响了此时训练以及后期推理的速度!
若按照原图像尺寸进行训练时出现出现“ CUDA out of memory "的报错,则可将长边长度和短边长度进行等比缩放。
短边长度/short side size:训练图像的短边像素长度。注意事项同上。每批图像张数/batch_size:训练时每次对权重文件进行一次迭代更新优化时所用的图像张数。该数据必须是 2 的整幂次倍,1、2、4、8…。适当的增加该数值能提升训练效果,但如果设置较大,往往可能超出独显显存导致训练时出现“ CUDA out of memory “的报错。以 8G 显存为例,在 img_size 参数设置为 640/360 或 1920/1080 时,可以将 batch_size 设为 4 或 2 。数据扩容倍数/data_cycle_times:对原始数据进行复制的倍数。在训练数据较少比如低于 100 张图像时,可以将该数值设为 2 或者 4 来达到增加图像数量的效果。训练循环次数/epoch_times:在上述复制的基础上,对所有原始数据训练一遍即为一次 epoch,该参数表示对所有训练数据重复使用的次数。每一次 epoch 结束都会将当前的权重文件进行临时保存。一般可以设置为 3、4、5 等。图像翻转方式/img_flip:数据增强——随机翻转原始图像。horizontal:水平翻转。
vertical:上下翻转。
none:禁用翻转。
是否随机裁剪/img_crop:数据增强——随机裁剪原始图像注意:裁剪后的保留比例已经固定为 0.9~1 。
基础模型配置文件/model_cfg_file:常规情况下置为空。当需要对某次的训练结果进行加训时,在这里输入上次训练结果的配置文件地址。基础模型权重文件/model_weights_file:常规情况下置为空。当需要加训时,在这里输入上次训练结果的权重文件地址。
功能演示
使用 AITrain 算子中 MaskRCNNTrain 对标注好的数据进行训练。
步骤1:算子准备
添加 Trigger、AITrain 算子至算子图。
步骤2:设置算子参数
设置 AITrain 算子参数:
类型 → MaskRCNNTrain
数据目录 →
 → 选择训练数据文件夹路径。( example_data/mask_data_train )
→ 选择训练数据文件夹路径。( example_data/mask_data_train )类名文件路径 →
→ 选择训练数据的类名文件地址。 ( example_data/mask_data_train/fruits.txt )长边长度 → 1920
短边长度 → 1080
每批图像张数 → 2
数据扩容倍数 → 4
训练循环次数 → 5
是否随机裁剪 →
→ True其余参数保持默认
步骤3:连接算子
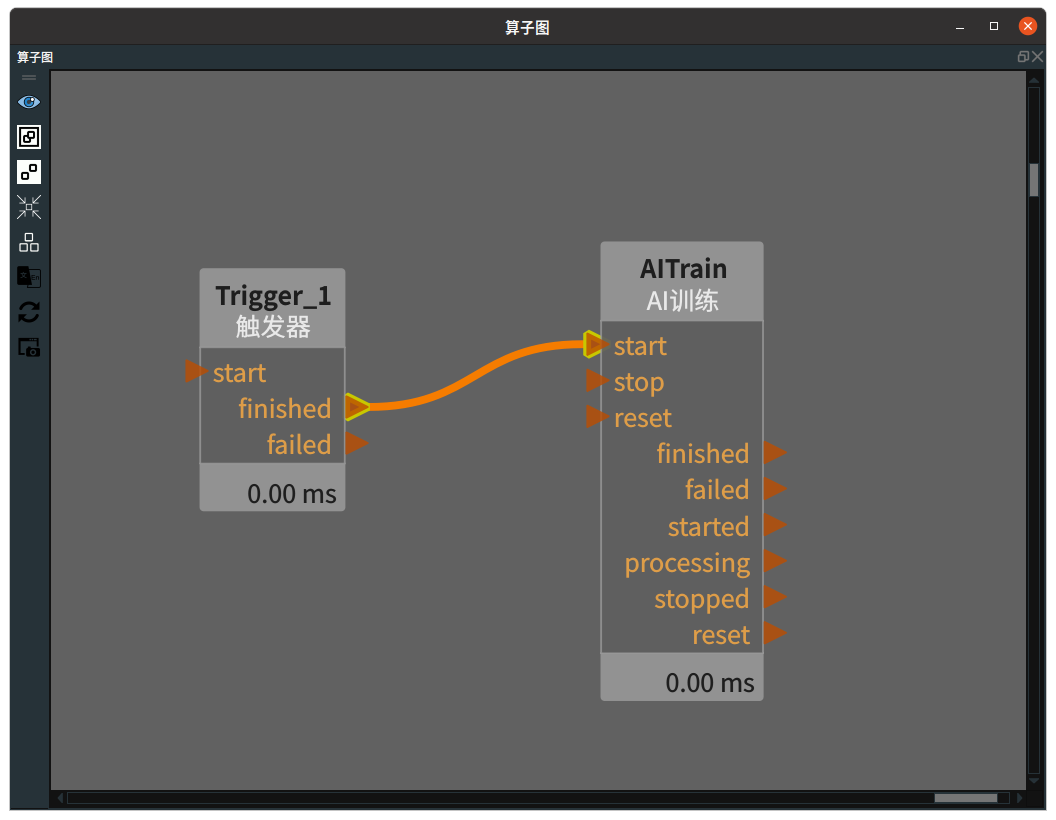
步骤4:运行
打开 RVS 的运行按钮,触发Trigger 算子。
运行结果
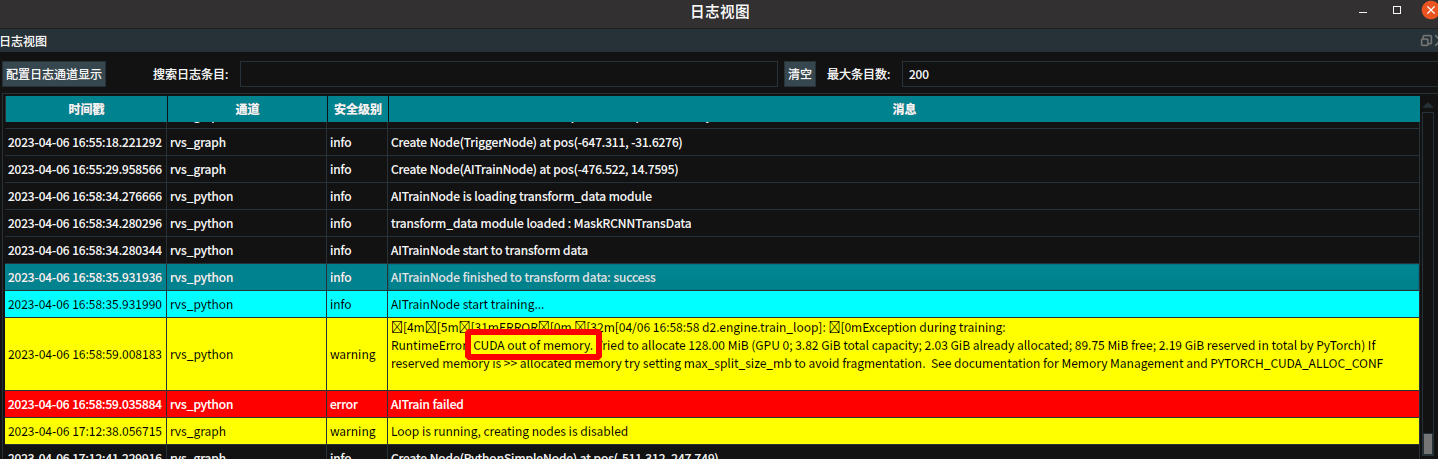
在训练过程中,算子呈现蓝色,同时在日志栏高亮打印输出信息。如果使用了 Windows / Linux 版本 启动RVS,则训练时还会在终端实时打印当前的训练进度,如下图所示。

训练完成后,算子呈现绿色,同时在日志栏高亮打印完成信息,RVS界面显示如下所示。
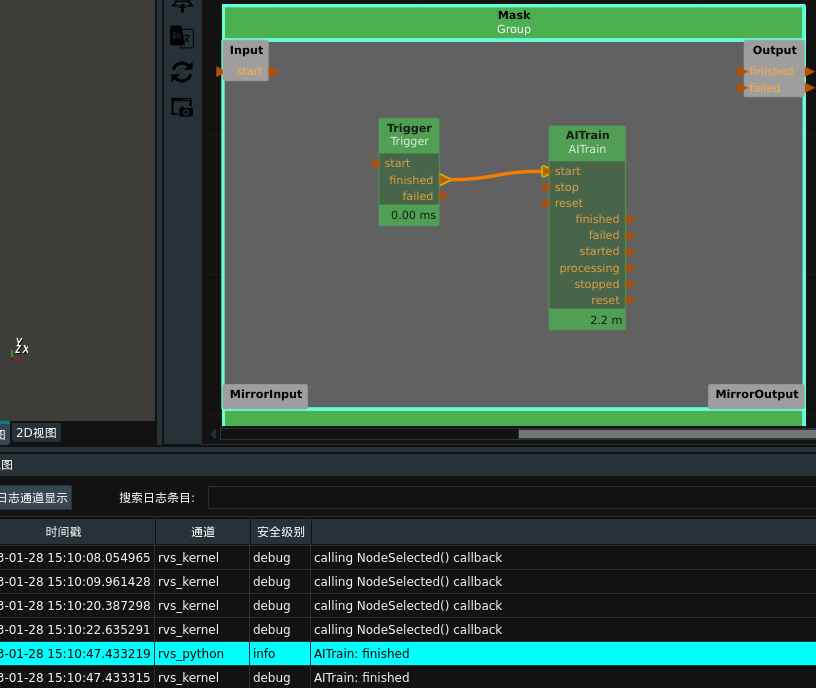
终端显示如下所示,在最后打印出 finished 。

说明
训练失败主要有以下三种情况。
1.请检查NIVDIA独立显卡是否正常运行。
2.出现“ CUDA out of memory "的报错。可以调整算子参数,可降低batch_size或者降低img_size.
3.初次训练需要联网下载预训练的权重文件,所以可能是网络异常导致下载失败。可进行如下检查:Linux 版本在根目录下搜索“model_final_f10217.pkl.lock”文件(Windows 版本在 C 盘目录下搜索该文件),检查该文件所在目录是否有“model_final_f10217.pkl”文件。如果没有“model_final_f10217.pkl”文件,可从 RVS 安装目录下的 rvs_sdk 文件夹内找到“model_final_f10217.pkl”文件,将该文件复制到“model_final_f10217.pkl.lock”文件所在目录下。再次进行训练即可。
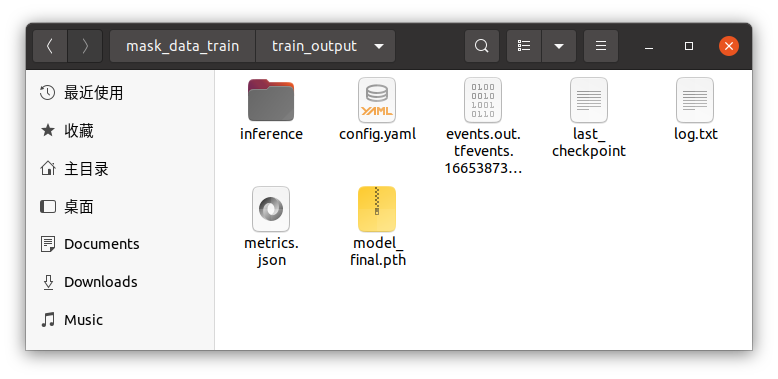
训练完成后,可在参数 data_directory 所在的文件夹内看到一个 train_output 的文件夹,其内容如下所示。其中,model_final.pth 是最终训练出来的网络权重文件,config.yaml 是对应的网络配置文件。
YOLOTrain
算子参数
数据目录/data_directory:同 MaskRCNNTrain 描述一致 。类名文件路径/classnames_filepath:以 yaml 为后缀名的文件(自行创建),内部必须包含“nc”以及“names”字段,分别表示类别数量以及类名名称,如下图所示。(注意,字段后面必须填写冒号以及空格)
特殊的,可以填写更多的训练参数到上述类名文件中,比如 mask_ratio 表示训练时的mask降采样比例,默认为1,不进行降采样。overlap_mask 表示是否允许 mask 之间存在重叠,默认为 True,允许重叠。
图像尺寸/image_size:同 MaskRCNNTrain 的 max_img_size/min_img_size 。区别:该网络在实际训练与推理的时候,默认将图像尺寸设为长宽一致。每批图像张数/batch_size:同 MaskRCNNTrain 的 batch_size 描述一致。注解
yolo网络相比于mask网络,需要更大的训练数据量以及更多的训练批次,所以训练时所用的数据量不应低于 100 。
训练循环次数/epoch_times:训练时所有数据使用一遍为一个epoch,该参数表示训练数据的最大循环次数。当训练数据中的所有目标个数低于200时,该参数一般设置为1000。其他情况一般设为 2000。注解
该网络没有默认设置自动提前终止训练(在某次训练结束后,后续的连续N次 epoch 没有获得训练提升则会自动提前终止训练)的功能,如果希望使用提前终止功能,需要在上述类名文件中增加patience关键字并设置对应的数量N。
train_model_mode:训练模型的尺寸规模,包含5种模型,tiny、small、medium、large\plus五类,模型规模依次越来越大,训练和推理的效果会越来越好,但是用时也会逐渐增加。目标种类较少、背景比较固定、光照比较均匀的简单情形,建议直接使用tiny即可。基础模型权重文件/model_weight_file:加训使用的基础模型。默认为空,不加训;如果加训,则这里需要填写一个之前训练好的权重文件,训练时会自动使用之前训练时候配置的训练参数(保留在该权重文件中),此次配置的训练参数无效。
功能演示
本节将使用 YOLOTrain 对标注好的数据进行训练。这与 MaskRCNNTrain 中展现的训练方法相同,请参照该章节的功能演示。
<div
注意
该网络模型训练完成后,会在参数类名文件路径所在的文件夹内看到一个 used_data 的文件夹以及一个 train_output 的文件夹,train_output/weights/last.pt 即为最终的训练权重文件。如下图所示:
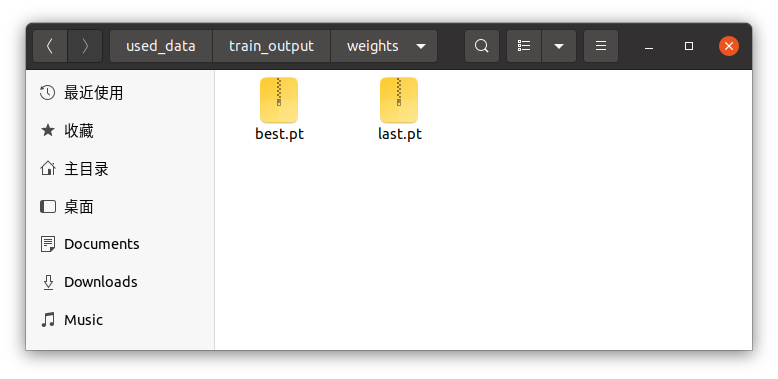
另外,每次训练时都会检查是否已经生成了used_data文件夹,该文件夹内存放了转换后的直接用于训练的数据,如果原始训练数据没有进行改动,进行重新训练时,不用手动删除该文件,此时程序会自动跳过数据格式转换的步骤。
KeyPointTrain
算子参数
类名文件路径/classnames_filepath:类名文件,训练所用的类名文件必须以 txt 作为文件后缀。每一个类名单独占一行。如果某个类别拥有关键点,则需要将关键点名依次用空格隔开填写到该类名所在行。例如:pear banana top bottom orange
则上述文件代表总共有三个类别分别为 pear、banana、orange,并且其中的 banana 类别的目标还具有 top 和 bottom 两个关键点。KeyPointTrain 算子仅允许给一个类别设置关键点。在特别的情况下,比如多个类别分别是 red_box、blue_box 、black_box,或者是man、woman这种,允许给这些多类别的对象同时设置关键点,但是要求他们的关键点保持一致,此时可以对这些不同颜色的箱子同时设置center、top的关键点,对人类同时设置头、左脚、右脚的关键点。
其余参数:同 MaskRCNNTrain 类型的描述一致 。
功能演示
本节将使用 KeyPointTrain 对标注好的数据进行训练。这与 MaskRCNNTrain 中展现的训练方法相同,请参照该章节的功能演示。