训练模型
MaskRCNN
用于 MaskRCNN 网络的训练,可以获得图像中目标的位置掩码(像素区域)。
每批图像张数:每次训练迭代中处理的图像数量。在训练过程中,选择合适的 每批图像张数对于优化性能和避免显存不足至关重要。以下是一些建议:
- 选择 每批图像张数:
- 每批图像张数 应为 2 的幂次,如 1、2、4、8 等。
- 较大的 每批图像张数 可以提高训练效果,但可能导致显存不足。
- 显存和图像尺寸的关系:
- 对于 8G 显存:
- 如果
长边/短边长度设置为 640/360,可以尝试将 每批图像张数 设为 4。 - 如果
长边/短边长度设置为 1920/1080,可以尝试将 每批图像张数 设为 2。
- 如果
- 对于 8G 显存:
- 调整策略:
- 如果遇到“CUDA out of memory”错误,尝试减小 每批图像张数。
- 监控显存使用情况,确保在安全范围内运行。
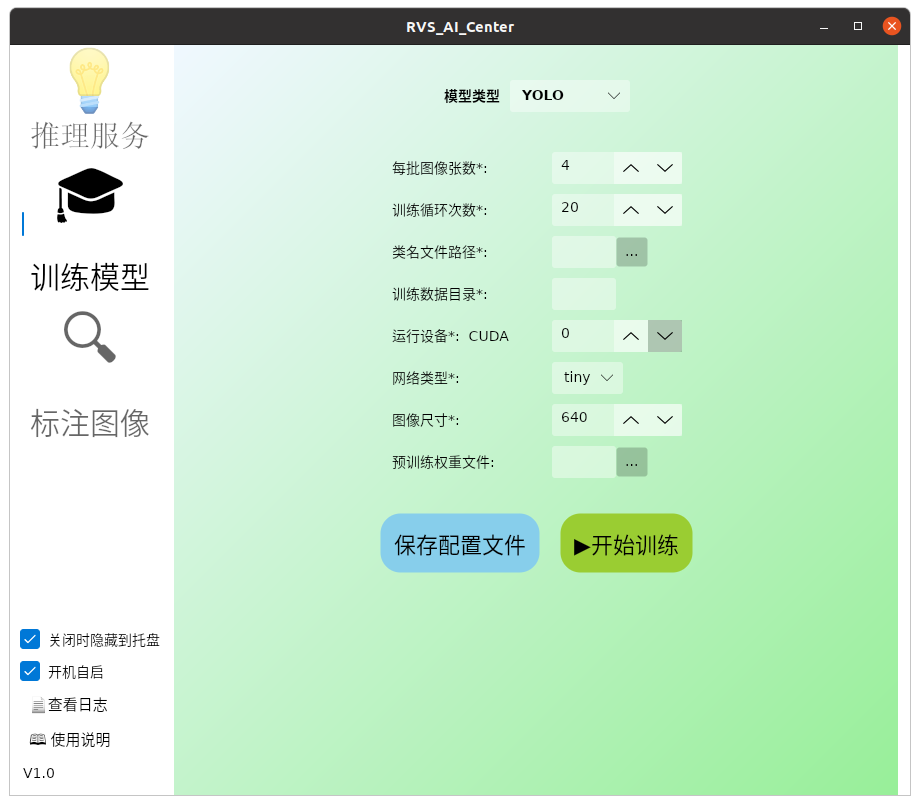
训练循环次数:整个数据集被训练的次数。类名文件路径:包含所有类别名称的文件路径。注意:训练所用的类名文件必须以 txt 作为文件后缀,文件中每一个类别名各自占一行。类名中不允许包含空格,且必须同标注文件中的类名保持一致。 路径中不支持中文与空格。训练数据目录:存储训练数据的目录路径。注意:该路径内包含多个子文件夹,每个子文件夹代表一组图像数据,其中必须包含有一张命名为 xxx.png 的图像以及一个命名为 xxx.json 的标注文件。运行设备:指定训练使用的独立显卡。若cuda输入的是0,表示选择第一块独立显卡进行训练。图像反转方式:图像增强中使用的反转方法。horizontal:水平翻转。vertical:上下翻转。none:禁用翻转。
是否随机裁剪:是否在训练中随机裁剪图像以增强数据。长边长度:调整图像尺寸时的目标长边长度。短边长度:调整图像尺寸时的目标短边长度。注意:在执行训练时,以及训练完成后进行推理时,算子都会首先将原图按照这里设定的尺寸进行缩放。所以这里的尺寸设置直接影响了此时训练以及后期推理的速度! 若按照原图像尺寸进行训练时出现出现“ CUDA out of memory "的报错,则可将长边长度和短边长度进行等比缩放。预训练配置文件:预训练模型的配置文件路径。常规情况下置为空。当需要对某次的训练结果进行加训时,在这里输入上次训练结果的配置文件地址。预训练权重文件:预训练模型的权重文件路径。常规情况下置为空。当需要加训时,在这里输入上次训练结果的权重文件地址。KeyPoint
用于关键点网络的训练,在 MaskRCNN 网络的基础上可以额外获得关键点的像素值。
参数与
MaskRCNN一致。YOLO
用于 YOLO 网络的训练,可以获得图像中目标位置的旋转矩形框。
每批图像张数:每次训练迭代中处理的图像数量。训练循环次数:整个数据集被训练的次数。该参数表示训练数据的最大循环次数。注意:yolo 网络相比于 mask 网络,需要更大的训练数据量以及更多的训练批次,所以训练时所用的数据量不应低于 100 。类名文件路径:以 yaml 为后缀名的文件(自行创建),内部必须包含“nc”以及“names”字段,分别表示类别数量以及类名名称,如下图所示。(注意,字段后面必须填写冒号以及空格)
特殊的,可以填写更多的训练参数到上述类名文件中,比如 mask_ratio 表示训练时的mask降采样比例,默认为1,不进行降采样。overlap_mask 表示是否允许 mask 之间存在重叠,默认为 True,允许重叠。
训练数据目录:存储训练数据的目录路径。注意:该路径内包含多个子文件夹,每个子文件夹代表一组图像数据,其中必须包含有一张命名为 xxx.png 的图像以及一个命名为 xxx.json 的标注文件。运行设备:指定训练使用的设备。网络类型:训练模型的尺寸规模,包含5种模型,tiny、small、medium、large、plus ,模型规模依次越来越大,训练和推理的效果会越来越好,但是用时也会逐渐增加。目标种类较少、背景比较固定、光照比较均匀的简单情形,建议直接使用tiny即可。tiny:轻量级版本,适用于资源有限的设备。计算速度快,但精度相对较低。适合实时性要求高的应用场景。samll:比 Tiny 稍大,提供更好的精度。仍然保持较快的推理速度。适用于需要平衡速度和精度的应用。medium:中等规模的模型,提供更高的精度。适合在有一定计算资源的情况下使用。适用于需要较高精度的应用场景。large:大规模模型,提供最高的精度。计算资源需求较高。适合对精度要求极高的应用。plus:增强版本,包含更多的层或更复杂的结构。提供最优的精度和性能。适用于高性能计算环境。
图像尺寸:指定输入图像的尺寸,长宽一致。预训练权重文件:预训练模型的权重文件路径。常规情况下置为空。当需要加训时,在这里输入上次训练结果的权重文件地址。
功能演示
使用 Mask RCNN 对标注好的数据进行训练。训练数据目录(mask_data_train)可以从 example_data 下载并解压。确保将数据放在合适的目录中,然后配置训练参数以开始训练。
训练参数填写如下图所示:
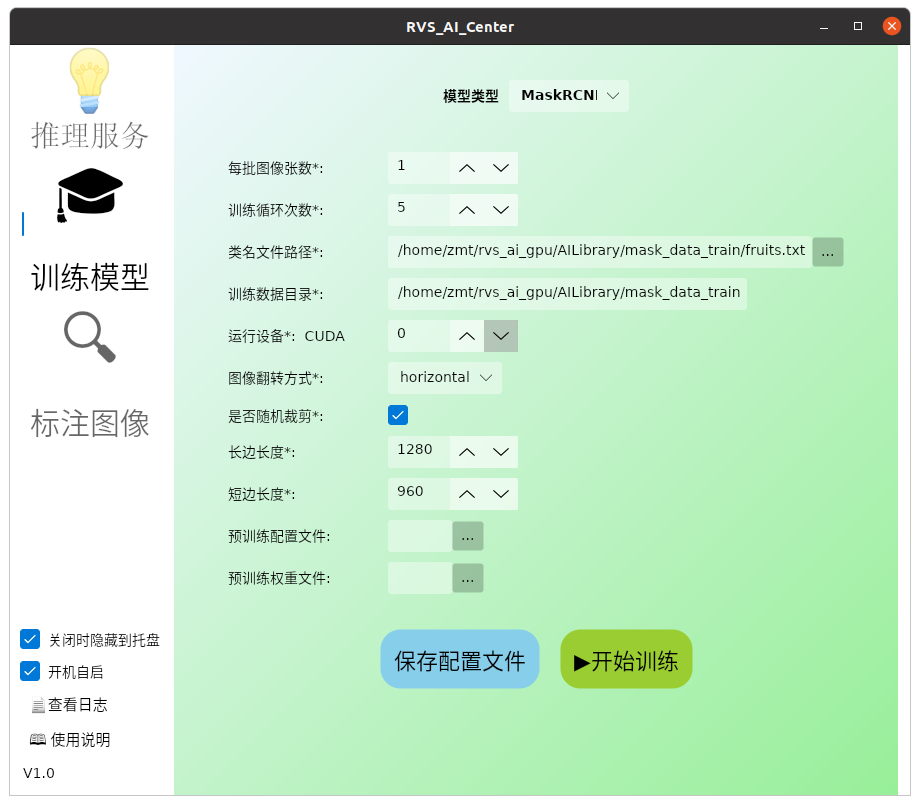
点击
保存配置文件后,再点击开始训练。训练过程中,终端会实时打印当前的训练进度,如下图所示。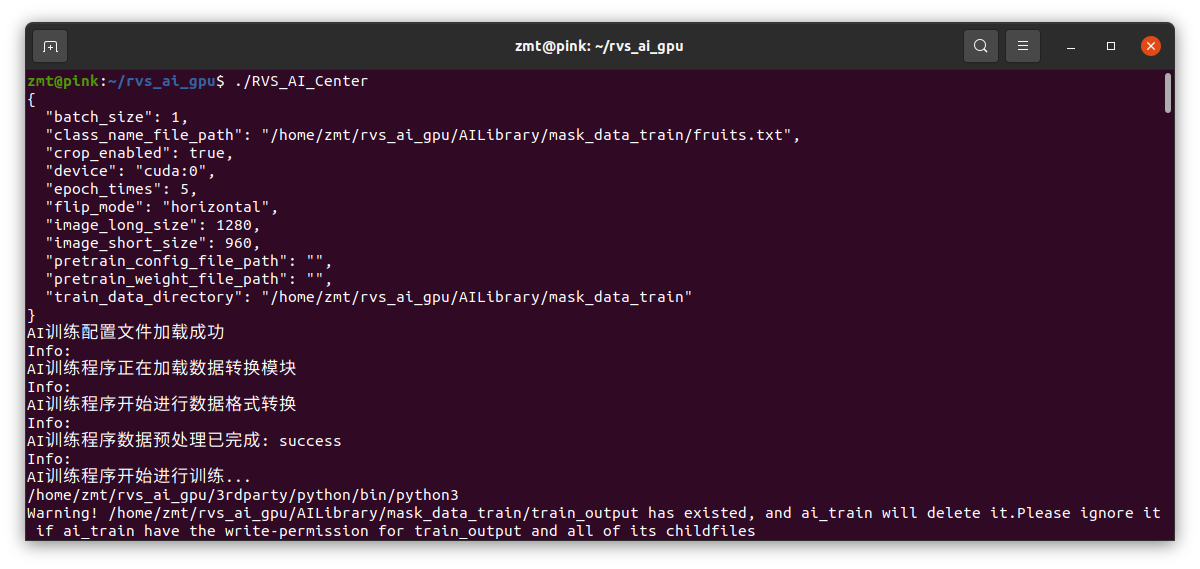
训练结束后,终端会显示如下信息,并在最后打印出“RVS_AI_Train_Finished”字样,表示训练过程已完成。
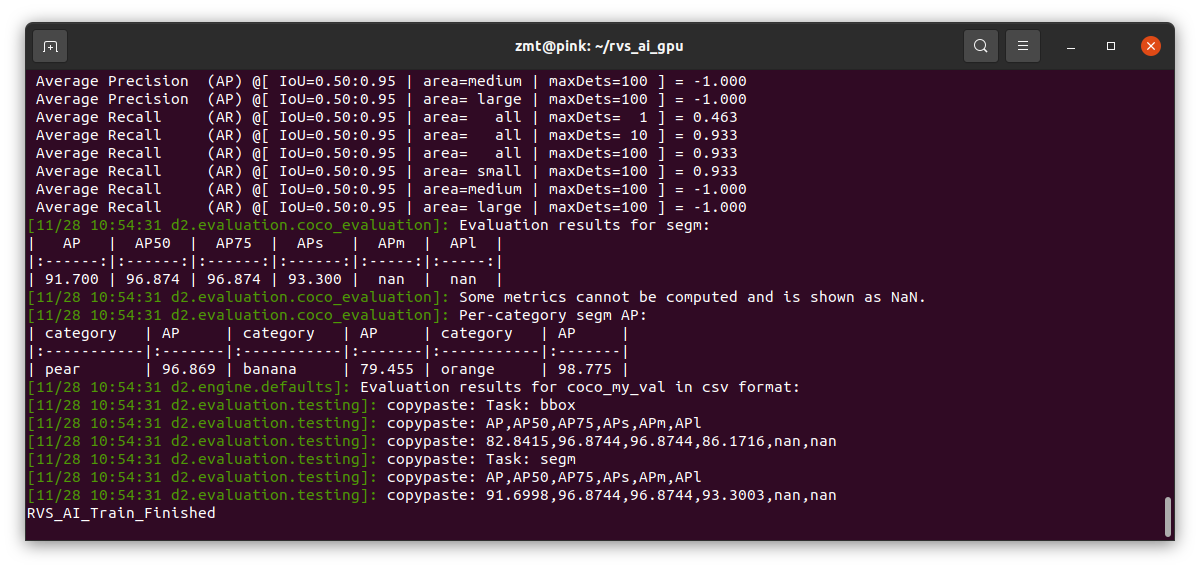
训练完成后,你会在训练数据目录下看到一个名为
result.mask的压缩包,该文件用于推理阶段。
训练失败的故障排查
确认和检查
确认GPU版本的RVS_AI安装包:
确保下载和安装的是支持 GPU 加速的版本。
检查当前使用的版本:
如果有多个版本,确保当前使用的是 GPU 版本。
Windows用户环境变量:
检查环境变量
$RVS_AI_ROOT是否正确设置为 GPU 版本的安装目录。
错误处理
CUDA Out of Memory
清理显存:
关闭其他占用显存的程序。
调整训练参数:
降低
每批图像张数或者调整长边长度、短边长度。
切换显卡:
如果有多个显卡,尝试在训练界面中切换使用不同的显卡(如
cuda:0到cuda:n)。
json.exception 或 FileNotFoundError
检查训练数据结构:
确保每张图像和标注文件在同一子文件夹中,且命名正确。
对于YOLO,图像命名为
rgb.png,标注为rgb.json。对于MaskRCNN/KeyPoint,图像和标注文件同名即可。
更新标注文件路径:
如果调整过文件名或目录,更新
json文件中的imagePath。
类名一致性:
确保标注时的类名与训练时一致(大小写敏感)。
使用支持的标注工具:
使用多边形、圆形或点标注工具。
CUDA Error
操作系统检查:
确保使用的是支持的操作系统(如Win11、Win10+update3、Ubuntu)。
显卡和驱动:
确保安装了NVIDIA GTX/RTX系列显卡和官方驱动。
显卡运行状态:
检查显卡是否正常运行并允许程序调用。
安装路径检查:
确保RVS_AI的安装路径和文件未被更改。
如果问题仍然存在,请考虑重新安装 RVS_AI 并确保所有设置正确。
- 选择 每批图像张数: